 程序设计实验室
微信公众号
程序设计实验室
微信公众号

前言
昨天在发布那篇《在鸡哥14x上安装Linux:Fedora 42 上手体验》的文章时
(使用 StarBlog Publisher 发布文章时)发现其中的 webp 图片都没法自动上传
一开始我以为是没法识别 webp 格式
关于 StarBlog Publisher 工具,这是一款面向 StarBlog 的跨平台 Markdown 文章发布工具,内置多种主流大模型智能助手,支持即写即发和直观内容管理,助力高效创作。
项目开源地址: https://github.com/star-blog/starblog-publisher
更多信息可以查看这些文章:
- StarBlog 番外篇 (3) StarBlog Publisher,跨平台一键发布,DeepSeek加持的文章创作神器
- StarBlog番外(4) 文章一键发布工具Publisher大升级,AI功能增强与界面优化
- AOT编译Avalonia应用:StarBlog Publisher项目实践与挑战
问题解决
后来写了几个 demo 测试后才发现,是因为文件名里有空格,而 Markdig 很严格,不支持识别带空格的文件名😂,要么就是在插入图片时(Typora 里)先转义,要么就得自己处理图片解析。
文章里的图片是这样的格式

后面我修改了 starblog-publisher 分析图片的方法
做了以下改进:
- 使用正则表达式
@"!\[([^\]]*)\]\(([^)]+)\)"匹配图片语法 - 支持路径中包含空格、中文字符等特殊字符
- 自动处理引号包围的路径和 URL 编码
代码
话不多说,直接上代码吧
先看原来的图片解析代码,完全使用 Markdig 来实现
/// <summary>
/// 从Markdown内容中提取所有图片路径
/// </summary>
/// <returns>图片路径数组</returns>
public string[] ExtractImagePaths() {
if (post.Content == null) {
return Array.Empty<string>();
}
var document = Markdig.Markdown.Parse(post.Content);
var imagePaths = new List<string>();
var baseDir = Path.GetDirectoryName(filepath) ?? "";
foreach (var node in document.AsEnumerable()) {
if (node is not ParagraphBlock { Inline: { } } paragraphBlock) continue;
foreach (var inline in paragraphBlock.Inline) {
if (inline is not LinkInline { IsImage: true } linkInline) continue;
if (string.IsNullOrWhiteSpace(linkInline.Url)) continue;
var imgUrl = Uri.UnescapeDataString(linkInline.Url);
// 如果是本地图片路径,转换为绝对路径
if (!imgUrl.StartsWith("http")) {
// 规范化路径
imgUrl = imgUrl.Replace('/', Path.DirectorySeparatorChar) // 统一路径分隔符
.Replace(".\\\\", "") // 移除相对路径前缀
.Replace("./", ""); // 移除相对路径前缀
imgUrl = Path.GetFullPath(Path.Combine(baseDir, imgUrl));
imagePaths.Add(imgUrl);
}
}
}
return imagePaths.ToArray();
}
自行实现图片解析
但 Markdig 实在是拉胯
那就只能我自己来实现解析了
也不难,用正则就可以了
/// <summary>
/// 提取带空格的图片路径(Markdig 无法正确解析的情况)
/// </summary>
/// <param name="content">Markdown 内容</param>
/// <param name="baseDir">基础目录</param>
/// <returns>图片路径列表</returns>
private List<string> ExtractImagePathsWithSpaces(string content, string baseDir) {
var imagePaths = new List<string>();
// 使用正则表达式匹配图片语法:
// 支持路径中包含空格、中文字符等
var imagePattern = @"!\[([^\]]*)\]\(([^)]+)\)";
var matches = System.Text.RegularExpressions.Regex.Matches(content, imagePattern);
foreach (System.Text.RegularExpressions.Match match in matches) {
if (match.Groups.Count >= 3) {
var imagePath = match.Groups[2].Value.Trim();
// 移除可能的引号
if ((imagePath.StartsWith('"') && imagePath.EndsWith('"')) ||
(imagePath.StartsWith('\'') && imagePath.EndsWith('\''))) {
imagePath = imagePath.Substring(1, imagePath.Length - 2);
}
// URL 解码
imagePath = Uri.UnescapeDataString(imagePath);
// 只处理本地路径
if (!imagePath.StartsWith("http")) {
// 规范化路径
imagePath = imagePath.Replace('/', Path.DirectorySeparatorChar)
.Replace(".\\\\", "")
.Replace("./", "");
var fullPath = Path.GetFullPath(Path.Combine(baseDir, imagePath));
imagePaths.Add(fullPath);
}
}
}
return imagePaths;
}
补充一下原方法
然后再补充一下原来 ExtractImagePaths 方法的代码
把底部的代码改成这样
// 添加自定义解析逻辑处理带空格的图片路径
// Markdig 无法正确解析带空格的图片路径,需要手动处理
var customPaths = ExtractImagePathsWithSpaces(post.Content, baseDir);
imagePaths.AddRange(customPaths);
// 去重并返回
return imagePaths.Distinct().ToArray();
实现效果
问题解决之后,可以正常识别到所有图片了
之前我在 starblog-publisher 里做了个画廊功能,可以很方便看到文章里的所有图片
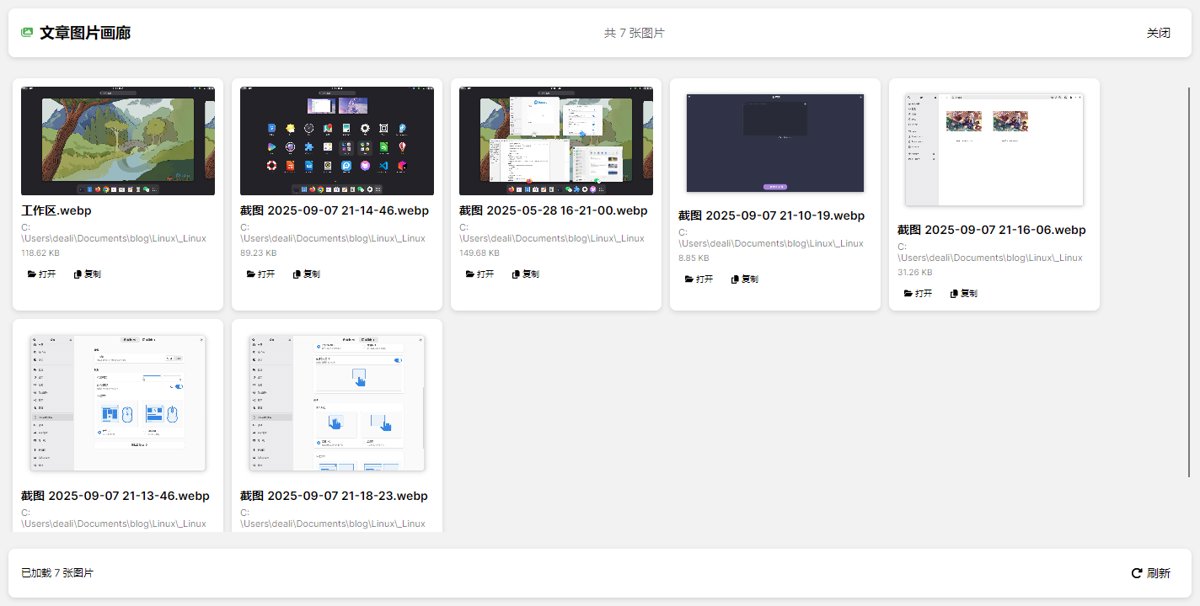
存在问题
使用正则表达式虽然简单粗暴,但有时会过于灵敏了
比如本文贴的代码里的 // 使用正则表达式匹配图片语法: 这一行注释,也会被识别到
就很烦,解决方法只能暂时是做成开关,由用户决定是否开启正则识别
只有当 Markdig 无法识别的情况下,才开启。然后再加一个忽略不存在的图片来解决。
开关
说干就干,我在设置里增加了一个开关
<!-- 图片解析设置卡片 -->
<Border Classes="Card">
<StackPanel Spacing="15" Margin="15">
<StackPanel Orientation="Horizontal" Spacing="8">
<i:Icon Value="fa-solid fa-image" Foreground="#FF9800" />
<TextBlock Text="图片解析设置" FontWeight="Bold" FontSize="16" />
</StackPanel>
<StackPanel Spacing="10">
<ToggleSwitch OnContent="启用正则识别" OffContent="仅使用标准识别"
IsChecked="{Binding EnableRegexImageParsing}" />
<TextBlock Text="启用后将使用正则表达式额外识别带空格的图片路径,但可能会过度识别。建议仅在需要处理特殊路径时开启。"
TextWrapping="Wrap"
FontSize="12"
Foreground="{DynamicResource SystemBaseMediumColor}"
Margin="0,5,0,0" />
</StackPanel>
</StackPanel>
</Border>
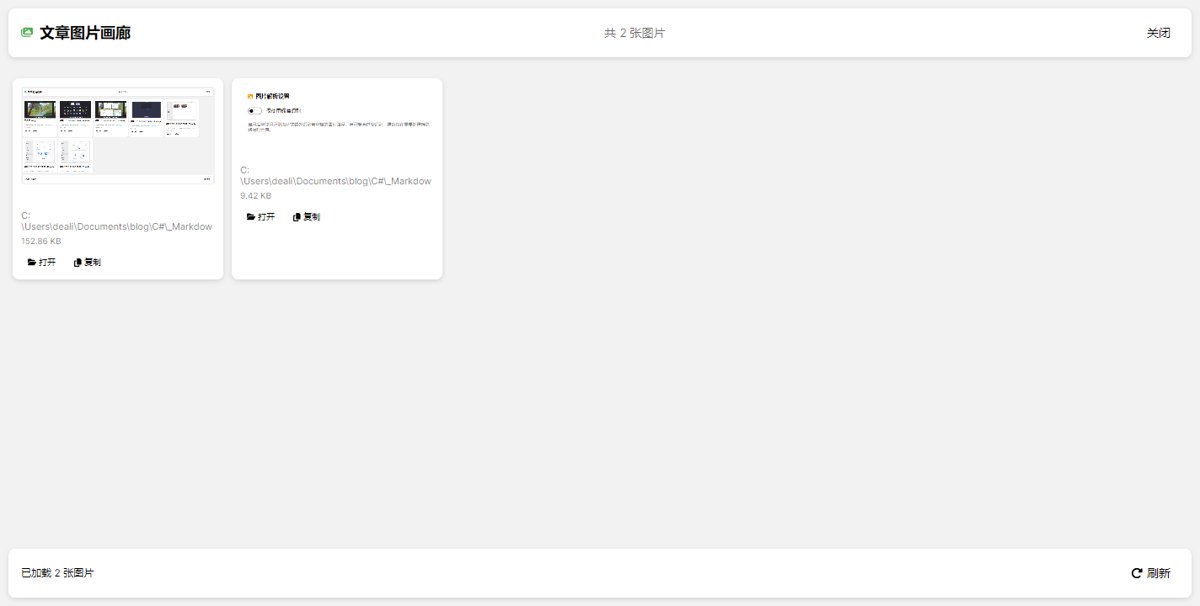
效果是这样的

不开启的情况下,识别出本文的图片就是这样的
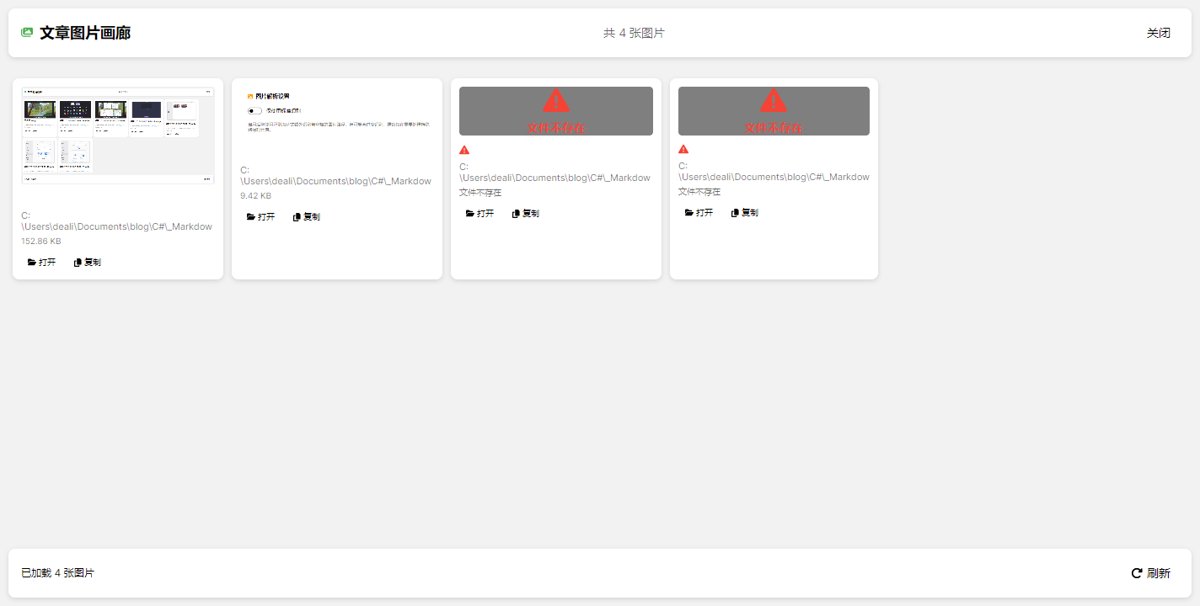
开启之后是这样,不存在的图片,我也加了标注
跳过不存在的
在 StarBlogPublisher/Services/MarkdownProcessor.cs 的 MarkdownParse 方法里添加代码
// 检查文件是否存在,跳过不存在的图片
if (!File.Exists(imgUrl)) {
Console.WriteLine($"跳过不存在的图片文件: {imgUrl}");
continue;
}
小结
做一个好用的工具,就是得不断迭代优化
不过我还是得吐槽一下,Markdig 像个毛坯房一样🤣