 程序设计实验室
微信公众号
程序设计实验室
微信公众号

前言
直接介绍了我折腾在【Windows系统 + AMD显卡】的多重 debuff 下尝试炼丹,最终成功编译出 ROCm 版本的 PyTorch,这意味着获得了进入炼丹界的钥匙。
接下来,为了验证我自己编译的 PyTorch 是否真正具备生产力,我们可以写一个经典的 MNIST 手写数字识别 脚本。
MNIST 手写数字识别(28x28 像素)被称为深度学习领域的“Hello World” 😄
这个脚本会包含:
- 显卡识别。
- 张量运算(测试 ROCm 内核)。
- 模型训练循环。
接下来我们分步介绍一下。
神经网络简介
先来科普一下。
神经网络是受人类大脑神经元连接方式启发的人工智能核心计算模型,由输入层、隐藏层和输出层构成的大量 “人工神经元” 相互连接而成。它通过模拟人脑信息处理逻辑,先由输入层接收图像、文本等原始数据,再经隐藏层逐层提取和转换特征,最后通过输出层输出分类、预测等结果。其核心优势在于具备自主学习能力,通过 “前向传播计算预测结果、反向传播调整连接权重” 的循环训练,不断优化模型精度,无需人工预设特征规则。如今,神经网络已广泛应用于生活各领域,从手机人脸解锁、智能语音助手,到医疗影像诊断、自动驾驶和个性化推荐,成为推动人工智能落地的关键技术。
我在网上看到一张很不错的图,可以清晰看到各种神经网络的结构。
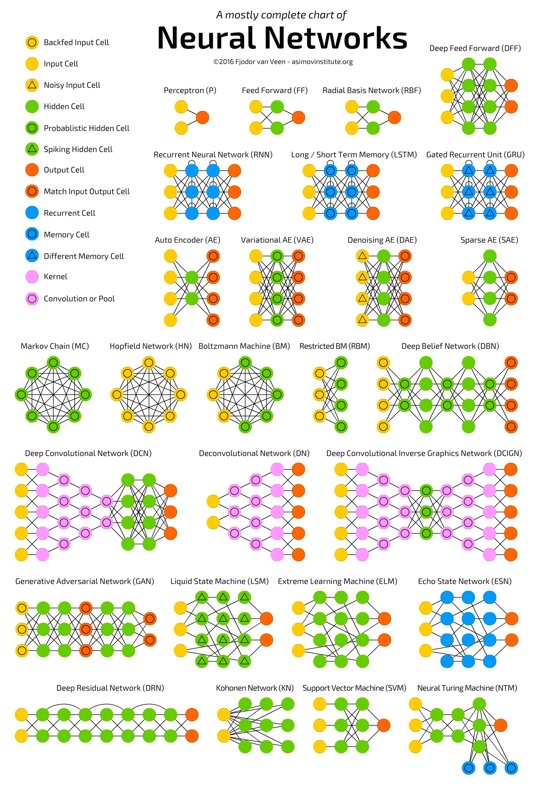
我记得刚学 Deep Learning 的时候,看了《Python 神经网络编程》这本书,里面作者教的是用 NumPy 手写了一个神经网络,包括后面同作者的另一本书《PyTorch 生成对抗网络》里用 PyTorch 实现的纯全连接层 MNIST 识别模型,都属于前馈神经网络(Feedforward Neural Network,FNN)(也常被称为多层感知机 MLP)。
而本文不用这种基础的网络,而是改成使用卷积神经网络(Convolutional Neural Network,CNN),更具体地说是 “卷积层 + 全连接层” 组合的基础 CNN 结构,这是 MNIST 手写数字识别任务中最经典、最常用的网络类型。
前馈神经网络(FNN/MLP)
- 是最基础的神经网络结构,无循环、无反馈,数据仅从输入层→隐藏层→输出层单向 “前馈” 流动;
- 处理图像时,会先把二维图像(如 28x28 的 MNIST)展平成一维向量(784 个元素),再通过全连接层(每个神经元与上一层所有神经元相连)进行计算;
卷积神经网络(CNN)
- 是专为网格状数据(图像、语音)设计的前馈网络变体,核心新增了卷积层、池化层,保留了前馈的核心逻辑,但优化了特征提取方式;
- 处理图像时不直接展平,而是通过卷积核 “滑动扫描” 图像,保留空间结构信息,再结合池化降维,最后才接入全连接层分类。
区别
两者核心差异在于是否保留空间结构和连接方式:FNN 全连接 + 展平,适合非空间数据;CNN 局部连接 + 权值共享,专为图像等空间数据设计。
| 维度 | 前馈神经网络(FNN / 纯全连接) | 卷积神经网络(CNN) |
|---|---|---|
| 数据处理方式 | 直接展平为一维向量,丢失空间信息 | 保留二维空间结构,卷积核扫描提取特征 |
| 连接方式 | 全连接:每个神经元与上一层所有神经元相连 | 局部连接 + 权值共享:卷积核仅连接局部区域,同一核参数复用 |
| 参数数量(MNIST) | 示例 FNN:784×128 + 128×64 + 64×10 = 109,328 | 示例 CNN:conv1 (1×32×3×3) + conv2 (32×64×3×3) + fc1 (9216×128) + fc2 (128×10) ≈ 1,219,624(看似多,但实际更大图像下 CNN 参数远少于 FNN) |
| 特征提取能力 | 只能学习全局特征,无法捕捉局部空间关系(如数字 “8” 的上下圈) | 分层提取特征:低层(边缘、线条)→高层(笔画、数字轮廓),精准捕捉空间特征 |
| 平移 / 变形鲁棒性 | 差:数字轻微位移就会被识别为不同特征 | 强:池化 + 卷积让模型对小位移、变形不敏感 |
| 适用场景 | 表格数据、简单分类(非空间数据) | 图像、视频、语音等网格 / 序列空间数据 |
CNN的优势
保留空间信息,特征提取更精准
FNN 把 28x28 的图像展平成 784 维向量后,数字 “5” 的顶部横线和右侧竖线的位置关系被完全打乱;而 CNN 的卷积层会 “看到” 这些局部结构,比如第一层卷积提取边缘,第二层提取笔画组合,最终识别更准确(MNIST 上 FNN 准确率约 97%,简单 CNN 可达 99%+)。
参数效率更高,避免过拟合
FNN 的全连接方式导致参数随输入尺寸暴增(比如把 MNIST 换成 256x256 图像,FNN 第一层参数会是 256×256×128=8,388,608,而 CNN 卷积层参数仅和卷积核数量 / 大小有关,与图像尺寸无关);CNN 的 “权值共享” 让同一卷积核复用在图像所有位置,大幅减少参数,降低过拟合风险。
天然具备平移不变性
比如 MNIST 中数字 “3” 稍微偏左或偏右,FNN 会认为是完全不同的输入(因为展平后向量位置变了),而 CNN 的卷积 + 池化会忽略这种小位移,依然能正确识别,耐操性更强。
安装 PyTorch
来复习一下,上一篇文章编译成功 PyTorch 之后,有几个产物。
按顺序安装这三个文件(注意:torch 必须最先安装)
pip install .\torch-2.9.1+rocm7.11.0a20260104-cp312-cp312-win_amd64.whl
pip install .\torchvision-0.24.0+rocm7.11.0a20260104-cp312-cp312-win_amd64.whl
pip install .\torchaudio-2.9.0+rocm7.11.0a20260104-cp312-cp312-win_amd64.whl
显卡识别和环境验证
首先激活之前 ComfyUI 的那个虚拟环境,也可以创建一个新的虚拟环境,我这里为了方便直接复用前面的虚拟环境。
使用以下代码检测显卡与环境。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import time
# 1. 验证 ROCm 环境
print("="*30)
print(f"PyTorch 版本: {torch.__version__}")
print(f"ROCm 是否可用: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"当前显卡: {torch.cuda.get_device_name(0)}")
print(f"AMD 架构: {torch.cuda.get_device_properties(0).gcnArchName if hasattr(torch.cuda.get_device_properties(0), 'gcnArchName') else 'N/A'}")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"正在使用设备: {device}")
print("="*30)
运行结果:
==============================
PyTorch 版本: 2.9.1+rocm7.11.0a20260104
ROCm 是否可用: True
当前显卡: AMD Radeon RX 6650 XT
AMD 架构: gfx1032
正在使用设备: cuda
==============================
nice!成功识别到显卡了!
定义模型
数字识别只需要最简单的CNN模型
# 2. 定义一个简单的 CNN 模型
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = torch.relu(self.conv1(x))
x = torch.relu(self.conv2(x))
x = torch.max_pool2d(x, 2)
x = torch.flatten(x, 1)
x = torch.relu(self.fc1(x))
return self.fc2(x)
准备数据
之前看书学习的时候害得自己去下载数据,现在 torchvision 包里直接自带了数据集。太舒服了!
# 3. 准备数据 (MNIST)
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
这个代码会把数据集加载到 data 目录里,效果:
data
└─ MNIST
└─ raw
├─ train-labels-idx1-ubyte.gz
├─ train-labels-idx1-ubyte
├─ train-images-idx3-ubyte.gz
├─ train-images-idx3-ubyte
├─ t10k-labels-idx1-ubyte.gz
├─ t10k-labels-idx1-ubyte
├─ t10k-images-idx3-ubyte.gz
└─ t10k-images-idx3-ubyte
训练模型
模型和数据准备好了,接下来开始训练
# 4. 初始化模型、损失函数和优化器
model = SimpleCNN().to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
# 5. 开始训练循环
print("\n开始在 AMD GPU 上进行训练测试...")
model.train()
start_time = time.time()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device) # 数据搬运到显存
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f'训练进度: [{batch_idx * len(data)}/{len(train_loader.dataset)}] \t损失: {loss.item():.6f}')
if batch_idx >= 500: # 只跑 500 个 batch 快速验证
break
end_time = time.time()
print("\n" + "="*30)
print(f"训练测试完成!耗时: {end_time - start_time:.2f} 秒")
print("="*30)
结果
完整代码的运行结果是这样的
$ python .\mnist.py
==============================
PyTorch 版本: 2.9.1+rocm7.11.0a20260104
ROCm 是否可用: True
当前显卡: AMD Radeon RX 6650 XT
AMD 架构: gfx1032
正在使用设备: cuda
==============================
开始在 AMD GPU 上进行训练测试...
训练进度: [0/60000] 损失: 2.297337
训练进度: [6400/60000] 损失: 0.120939
训练进度: [12800/60000] 损失: 0.053362
训练进度: [19200/60000] 损失: 0.040536
训练进度: [25600/60000] 损失: 0.087424
训练进度: [32000/60000] 损失: 0.036002
==============================
训练测试完成!耗时: 5.61 秒
==============================
小结
一个非常好的开始,虽然这个任务对这个显卡来说已经太简单了,不过这一步就直接开启了A卡玩深度学习的大门,接下来我会继续更新AMD显卡搭配深度学习的玩法。
上一篇文章看到有同学要用AI画图生成doll姐的封面图🐶
等我把 Z-Image 工作流跑通就来安排🐶