 程序设计实验室
微信公众号
程序设计实验室
微信公众号

交叉算子
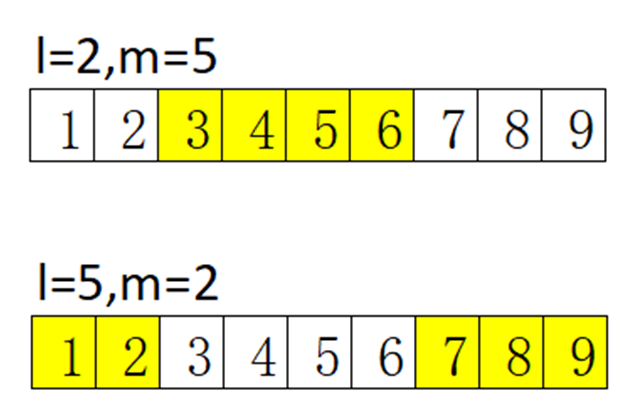
在常见的交叉算子中,经常会有选取基因片段的操作,有的是连续选取,有的是不连续选取,对于连续选取的交叉算子,我使用的都是环形选择,具体操作是这样的:首先给定起点l和终点m,以及基因长度L,如果l<m,则选取l到m这段基因;如果l>m,则选取0到m和l到L这两段基因,这样可以保证每一“碱基对”被选到的概率是相等的。
交叉算子这里我主要参考的是: https://blog.csdn.net/u012750702/article/details/54563515
以下大部分内容都摘自该网站,当然也有一小部分我自己的理解。
Partial-Mapped Crossover(PMX)
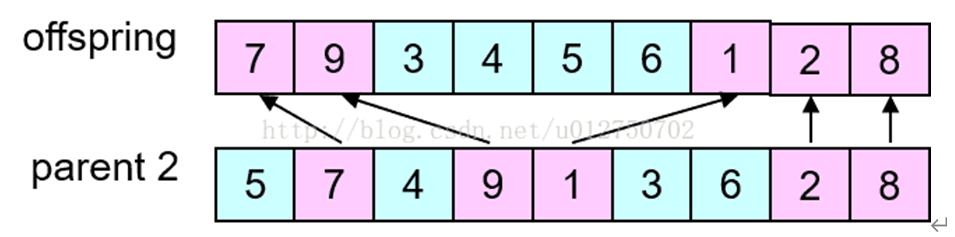
这个交叉算子使用的是连续选取,具体过程是这样的: 第一步,随机选择一对染色体(父代)中几个基因的起止位置(两染色体被选位置相同):

第二步,交换这两组基因的位置:

第三步,做冲突检测,根据交换的两组基因建立一个映射关系,如图所示,以1-6-3这一映射关系为例,可以看到第二步结果中子代1存在两个基因1,这时将其通过映射关系转变为基因3,以此类推至没有冲突为止。最后所有冲突的基因都会经过映射,保证形成的新一对子代基因无冲突:

最终结果:

这个交叉算子最关键的就是第三部的冲突检测了,我采取的方法是先用一个字典来储存每个“碱基”对应的“碱基”,比如在上面例子中,我储存的字典为
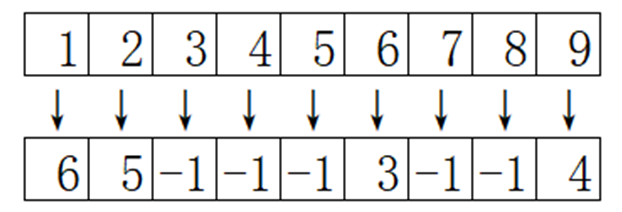
对于这样的一个映射表,我想找出“1”对应的数字,我只需要循环嵌套判断,“1”对应的数字是“6”,“6”对应的数字是“3”,“3”对应的数字是“-1”,循环停止,所以我找到了“1”最终对应的数字是“3”,如此便实现了冲突检测。
/// <summary>
/// PMX交叉算子
/// </summary>
/// <param name="parent1">父类基因一</param>
/// <param name="parent2">父类基因二</param>
/// <returns>基因片段</returns>
public static List<int[]> PMX(int[] parent1, int[] parent2)
{
List<int[]> ans = new List<int[]>();
int[] a = new int[parent1.Length], ans1 = new int[parent1.Length], ans2 = new int[parent1.Length];
int l, m, num;
for (int i = 0; i < parent1.Length; i++)
{
a[i] = i;
}
a = a.OrderBy(c => Guid.NewGuid()).ToArray();
l = a[0];
m = a[1];
Dictionary<int, int> dict1 = new Dictionary<int, int>(), dict2 = new Dictionary<int, int>();
for (int i = 1; i <= parent1.Length; i++)
{
dict1[i] = -1;
dict2[i] = -1;
}
if (l < m)
{
for (int i = l; i < m; i++)
{
ans1[i] = parent2[i];
ans2[i] = parent1[i];
dict1[parent2[i]] = parent1[i];
dict2[parent1[i]] = parent2[i];
}
for (int i = 0; i < l; i++)
{
num = parent1[i];
while (dict1[num] != -1)
{
num = dict1[num];
}
ans1[i] = num;
num = parent2[i];
while (dict2[num] != -1)
{
num = dict2[num];
}
ans2[i] = num;
}
for (int i = m; i < parent1.Length; i++)
{
num = parent1[i];
while (dict1[num] != -1)
{
num = dict1[num];
}
ans1[i] = num;
num = parent2[i];
while (dict2[num] != -1)
{
num = dict2[num];
}
ans2[i] = num;
}
}
else
{
for (int i = 0; i < m; i++)
{
ans1[i] = parent2[i];
ans2[i] = parent1[i];
dict1[parent2[i]] = parent1[i];
dict2[parent1[i]] = parent2[i];
}
for (int i = l; i < parent1.Length; i++)
{
ans1[i] = parent2[i];
ans2[i] = parent1[i];
dict1[parent2[i]] = parent1[i];
dict2[parent1[i]] = parent2[i];
}
for (int i = m; i < l; i++)
{
num = parent1[i];
while (dict1[num] != -1)
{
num = dict1[num];
}
ans1[i] = num;
num = parent2[i];
while (dict2[num] != -1)
{
num = dict2[num];
}
ans2[i] = num;
}
}
ans.Add(ans1);
ans.Add(ans2);
return ans;
}
Order Crossover (OX)
这个算子使用的也是连续选取,具体过程如下:
第一步,与PMX相同,随机选择一对染色体(父代)中几个基因的起止位置(两染色体被选位置相同):

第二步,生成一个子代,并保证子代中被选中的基因的位置与父代相同:

第三步(可再分两小步),先找出第一步选中的基因在另一个父代中的位置,再将其余基因按顺序放入上一步生成的子代中:
需要注意的是,这种算法同样会生成两个子代,另一个子代生成过程完全相同,只需要将两个父代染色体交换位置,第一步选中的基因型位置相同,本例中的另一个子代为:254913678
与PMX不同的是,不用进行冲突检测工作(实际上也只有PMX需要做冲突检测)。
/// <summary>
/// OX交叉算子
/// </summary>
/// <param name="parent1">父类基因一</param>
/// <param name="parent2">父类基因二</param>
/// <returns>基因片段</returns>
public static List<int[]> OX(int[] parent1, int[] parent2)
{
List<int[]> ans = new List<int[]>();
int[] a = new int[parent1.Length], ans1 = new int[parent1.Length], ans2 = new int[parent1.Length];
int l, m;
for (int i = 0; i < parent1.Length; i++)
{
a[i] = i;
}
a = a.OrderBy(c => Guid.NewGuid()).ToArray();
l = a[0];
m = a[1];
if (l < m)
{
HashSet<int> set1 = new HashSet<int>(), set2 = new HashSet<int>();
int j = 0, k = 0;
for (int i = l; i < m; i++)
{
ans2[i] = parent2[i];
set2.Add(parent2[i]);
ans1[i] = parent1[i];
set1.Add(parent1[i]);
}
for (int i = 0; i < l; i++)
{
while (set1.Contains(parent2[j]))
{
j++;
}
ans1[i] = parent2[j];
j++;
while (set2.Contains(parent1[k]))
{
k++;
}
ans2[i] = parent1[k];
k++;
}
for (int i = m; i < parent1.Length; i++)
{
while (set1.Contains(parent2[j]))
{
j++;
}
ans1[i] = parent2[j];
j++;
while (set2.Contains(parent1[k]))
{
k++;
}
ans2[i] = parent1[k];
k++;
}
}
else
{
HashSet<int> set1 = new HashSet<int>(), set2 = new HashSet<int>();
int j = 0, k = 0;
for (int i = 0; i < m; i++)
{
ans2[i] = parent2[i];
set2.Add(parent2[i]);
ans1[i] = parent1[i];
set1.Add(parent1[i]);
}
for (int i = l; i < parent1.Length; i++)
{
ans2[i] = parent2[i];
set2.Add(parent2[i]);
ans1[i] = parent1[i];
set1.Add(parent1[i]);
}
for (int i = m; i < l; i++)
{
while (set1.Contains(parent2[j]))
{
j++;
}
ans1[i] = parent2[j];
j++;
while (set2.Contains(parent1[k]))
{
k++;
}
ans2[i] = parent1[k];
k++;
}
}
ans.Add(ans1);
ans.Add(ans2);
return ans;
}
Position-based Crossover (PBX)
这个算子是不连续选取的,具体过程如下:
第一步,随机选择一对染色体(父代)中几个基因,位置可不连续,但两染色体被选位置相同:

第二步,与OX的第二步相同,生成一个子代,并保证子代中被选中的基因的位置与父代相同:

第三步,也与OX的第三步相同,先找出第一步选中的基因在另一个父代中的位置,再将其余基因按顺序放入上一步生成的子代中:
与上俩个算法不同的是,选择的基因型位置可以不连续,出来这一点外与OX基本一致,同样有两个子代,本例的另一个为:243519678。
/// <summary>
/// PBX交叉算子
/// </summary>
/// <param name="parent1">父类基因一</param>
/// <param name="parent2">父类基因二</param>
/// <returns>基因片段</returns>
public static List<int[]> PBX(int[] parent1, int[] parent2)
{
List<int[]> ans = new List<int[]>();
int[] a = new int[parent1.Length], ans1 = new int[parent1.Length], ans2 = new int[parent1.Length];
for (int i = 0; i < parent1.Length; i++)
{
a[i] = i;
}
a = a.OrderBy(c => Guid.NewGuid()).ToArray();
int r = rand_int(0, parent1.Length);
HashSet<int> set = new HashSet<int>(), set1 = new HashSet<int>(), set2 = new HashSet<int>();
for (int i = 0; i < r; i++)
{
set.Add(a[i]);
}
foreach (var i in set)
{
ans2[i] = parent2[i];
set2.Add(parent2[i]);
ans1[i] = parent1[i];
set1.Add(parent1[i]);
}
int j = 0, k = 0;
for (int i = 0; i < parent1.Length; i++)
{
if (set.Contains(i))
{
continue;
}
while (set1.Contains(parent2[j]))
{
j++;
}
ans1[i] = parent2[j];
j++;
while (set2.Contains(parent1[k]))
{
k++;
}
ans2[i] = parent1[k];
k++;
}
ans.Add(ans1);
ans.Add(ans2);
return ans;
}
Order-Based Crossover (OBX)
这个算子是不连续选取的,具体过程如下:
第一步,随机选择一对染色体(父代)中几个基因,位置可不连续,但两染色体被选位置相同:

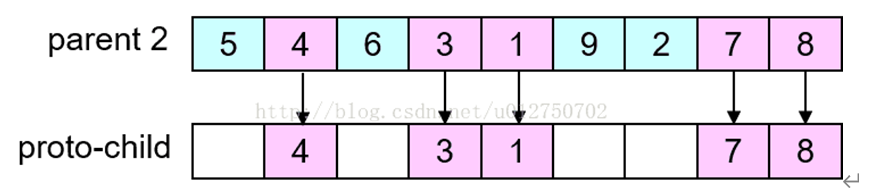
第二步(分为两小步),先在父代2中找到父代1被选中基因的位置,再用父代2中其余的基因生成子代,并保证位置对应:
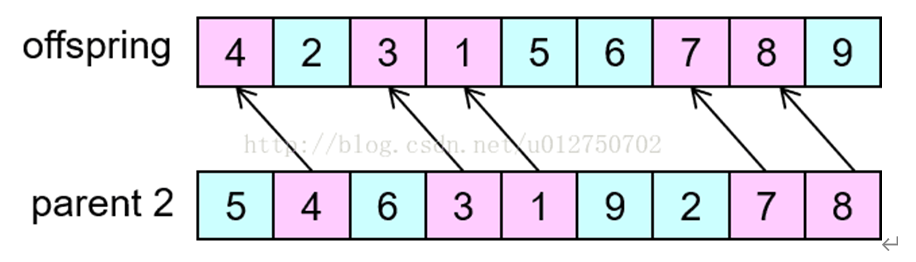
第三步,将父代1中被选择的基因按顺序放入子代剩余位置中:
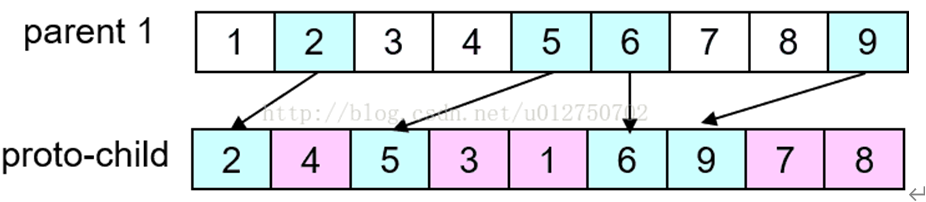
同理,交换父代1、2可得到另一个子代(被选择基因的位置不变),本例结果为:423156798。
OBX与PBX相比生成子代的“基础”基因来源不同一个来自被选中基因,一个来自剩余的,此外思想基本相似。
/// <summary>
/// OBX交叉算子
/// </summary>
/// <param name="parent1">父类基因一</param>
/// <param name="parent2">父类基因二</param>
/// <returns>基因片段</returns>
public static List<int[]> OBX(int[] parent1, int[] parent2)
{
List<int[]> ans = new List<int[]>();
int[] a = new int[parent1.Length], ans1 = new int[parent1.Length], ans2 = new int[parent1.Length];
int l, m;
for (int i = 0; i < parent1.Length; i++)
{
a[i] = i;
}
a = a.OrderBy(c => Guid.NewGuid()).ToArray();
int r = rand_int(0, parent1.Length);
HashSet<int> set1 = new HashSet<int>(), set2 = new HashSet<int>();
List<int> set = new List<int>();
for (int i = 0; i < r; i++)
{
set.Add(a[i]);
}
foreach (var i in set)
{
set1.Add(parent1[i]);
set2.Add(parent2[i]);
}
int j = 0, k = 0;
for (int i = 0; i < parent2.Length; i++)
{
if (!set1.Contains(parent2[i]))
{
ans1[i] = parent2[i];
}
else
{
ans1[i] = parent1[set[j]];
j++;
}
if (!set2.Contains(parent1[i]))
{
ans2[i] = parent1[i];
}
else
{
ans2[i] = parent2[set[k]];
k++;
}
}
ans.Add(ans1);
ans.Add(ans2);
return ans;
}
Cycle Crossover (CX)
这个算子具体过程如下:
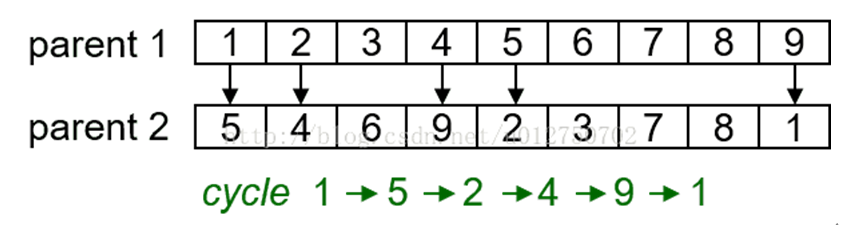
第一步,在某个父代上随机选择1个基因,然后找到另一个父代相应位置上的基因编号,再回到第一个父代找到同编号的基因的位置,重复先前工作,直至形成一个环,环中的所有基因的位置即为最后选中的位置:
第二步,用父代1中选中的基因生成子代,并保证位置对应:

第三步,将父代2中剩余基因放入子代中:
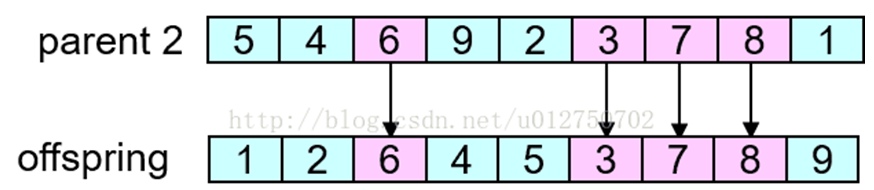
与上述算法不同的是,仅需要在一个染色体上随机选择一个位置;本例另一个子代结果为:543926781。
这里的寻找闭环的过程其实和PMX中的冲突检测有点类似,也是循环嵌套判断罢了。
/// <summary>
/// CX交叉算子
/// </summary>
/// <param name="parent1">父类基因一</param>
/// <param name="parent2">父类基因二</param>
/// <returns>基因片段</returns>
public static List<int[]> CX(int[] parent1, int[] parent2)
{
int r = rand_int(0, parent1.Length);
List<int[]> ans = new List<int[]>();
int[] ans1 = new int[parent1.Length], ans2 = new int[parent1.Length];
Dictionary<int, int> dict = new Dictionary<int, int>();
for (int i = 0; i < parent1.Length; i++)
{
dict[parent1[i]] = i;
}
Dictionary<int, int> a = new Dictionary<int, int>();
HashSet<int> set = new HashSet<int>();
a[parent1[r]] = parent2[r];
int num = parent2[r];
ans1[r] = parent1[r];
ans2[r] = parent2[r];
set.Add(dict[parent1[r]]);
while (parent2[dict[num]] != parent1[r])
{
a[num] = parent2[dict[num]];
ans1[dict[num]] = num;
ans2[dict[num]] = parent2[dict[num]];
set.Add(dict[num]);
num = a[num];
}
set.Add(dict[num]);
ans1[dict[num]] = num;
ans2[dict[num]] = parent2[dict[num]];
for (int i = 0; i < parent1.Length; i++)
{
if (!set.Contains(i))
{
ans1[i] = parent2[i];
ans2[i] = parent1[i];
}
}
ans.Add(ans1);
ans.Add(ans2);
return ans;
}
Subtour Exchange Crossover(SEC)
这个算子是连续选取的,具体过程如下:
第一步,在某个父代上选择1组基因,在另一父代上找到这些基因的位置:

第二步,保持未选中基因不变,按选中基因的出现顺序,交换两父代染色体中基因的位置,一次生成两个子代:

与上述算法不同的是,只在一个染色体上选择基因的位置。
/// <summary>
/// SEC交叉算子
/// </summary>
/// <param name="parent1">父类基因一</param>
/// <param name="parent2">父类基因二</param>
/// <returns>基因片段</returns>
public static List<int[]> SEC(int[] parent1, int[] parent2)
{
List<int[]> ans = new List<int[]>();
int[] a = new int[parent1.Length], ans1 = new int[parent1.Length], ans2 = new int[parent1.Length];
int l, m, t;
for (int i = 0; i < parent1.Length; i++)
{
a[i] = i;
ans1[i] = parent1[i];
ans2[i] = parent2[i];
}
a = a.OrderBy(c => Guid.NewGuid()).ToArray();
l = a[0];
m = a[1];
Dictionary<int, int> dict = new Dictionary<int, int>();
for (int i = 0; i < parent1.Length; i++)
{
dict[parent2[i]] = i;
}
List<int> index = new List<int>();
if (l < m)
{
for (int i = l; i < m; i++)
{
index.Add(dict[parent1[i]]);
}
index.Sort();
for (int i = 0; i < m - l; i++)
{
t = ans1[l + i];
ans1[l + i] = ans2[index[i]];
ans2[index[i]] = t;
}
}
else
{
for (int i = 0; i < m; i++)
{
index.Add(dict[parent1[i]]);
}
for (int i = l; i < parent1.Length; i++)
{
index.Add(dict[parent1[i]]);
}
index.Sort();
for (int i = 0; i < m; i++)
{
t = ans1[i];
ans1[i] = ans2[index[i]];
ans2[index[i]] = t;
}
for (int i = 0; i < parent1.Length - l; i++)
{
t = ans1[l + i];
ans1[l + i] = ans2[index[m + i]];
ans2[index[m + i]] = t;
}
}
ans.Add(ans1);
ans.Add(ans2);
return ans;
}
其他交叉算子
以上算法都是针对int数组类型的基因的处理,而对于bool数组类型的基因,处理起来就很简单了,选取基因片段进行交换就行了,同样道理可以连续选取也可以不连续选取。
/// <summary>
/// OX交叉算子
/// </summary>
/// <param name="parent1">父类基因一</param>
/// <param name="parent2">父类基因二</param>
/// <returns>基因片段</returns>
public static List<bool[]> OX(bool[] parent1, bool[] parent2)
{
List<bool[]> ans = new List<bool[]>();
int[] a = new int[parent1.Length];
bool[] ans1 = new bool[parent1.Length], ans2 = new bool[parent2.Length];
int l, m;
for (int i = 0; i < parent1.Length; i++)
{
a[i] = i;
}
a = a.OrderBy(c => Guid.NewGuid()).ToArray();
l = a[0];
m = a[1];
if (l < m)
{
for (int i = l; i < m; i++)
{
ans1[i] = parent2[i];
ans2[i] = parent1[i];
}
for (int i = 0; i < l; i++)
{
ans1[i] = parent1[i];
ans2[i] = parent2[i];
}
for (int i = m; i < parent1.Length; i++)
{
ans1[i] = parent1[i];
ans2[i] = parent2[i];
}
}
else
{
for (int i = 0; i < m; i++)
{
ans1[i] = parent2[i];
ans2[i] = parent1[i];
}
for (int i = l; i < parent1.Length; i++)
{
ans1[i] = parent2[i];
ans2[i] = parent1[i];
}
for (int i = m; i < l; i++)
{
ans1[i] = parent1[i];
ans2[i] = parent2[i];
}
}
ans.Add(ans1);
ans.Add(ans2);
return ans;
}
/// <summary>
/// PBX交叉算子
/// </summary>
/// <param name="parent1">父类基因一</param>
/// <param name="parent2">父类基因二</param>
/// <returns>基因片段</returns>
public static List<bool[]> PBX(bool[] parent1, bool[] parent2)
{
List<bool[]> ans = new List<bool[]>();
int[] a = new int[parent1.Length];
bool[] ans1 = new bool[parent1.Length], ans2 = new bool[parent2.Length];
for (int i = 0; i < parent1.Length; i++)
{
a[i] = i;
}
a = a.OrderBy(c => Guid.NewGuid()).ToArray();
int r = rand_int(0, parent1.Length);
HashSet<int> set = new HashSet<int>(), set1 = new HashSet<int>(), set2 = new HashSet<int>();
for (int i = 0; i < r; i++)
{
set.Add(a[i]);
}
for (int i = 0; i < parent1.Length; i++)
{
if (set.Contains(i))
{
ans1[i] = parent2[i];
ans2[i] = parent1[i];
}
else
{
ans1[i] = parent1[i];
ans2[i] = parent2[i];
}
}
ans.Add(ans1);
ans.Add(ans2);
return ans;
}
变异算子
变异操作相对来说就简单很多了,对于int数组类型的基因只需要选取基因片段(连续or不连续)进行重新排列,对于bool数组类型的基因只需要选取基因片段(连续or不连续)进行取反操作即可。
/// <summary>
/// OX变异算子
/// </summary>
/// <param name="gene">基因片段</param>
/// <returns>基因片段</returns>
public static int[] Variation_OX(int[] gene)
{
int[] a = new int[gene.Length], ans = new int[gene.Length];
int l, m;
for (int i = 0; i < gene.Length; i++)
{
a[i] = i;
}
a = a.OrderBy(c => Guid.NewGuid()).ToArray();
l = a[0];
m = a[1];
List<int> b = new List<int>();
if (l < m)
{
for (int i = l; i < m; i++)
{
b.Add(gene[i]);
}
b = b.OrderBy(c => Guid.NewGuid()).ToList();
for (int i = 0; i < l; i++)
{
ans[i] = gene[i];
}
for (int i = 0; i < m - l; i++)
{
ans[l + i] = b[i];
}
for (int i = m; i < gene.Length; i++)
{
ans[i] = gene[i];
}
}
else
{
for (int i = 0; i < m; i++)
{
b.Add(gene[i]);
}
for (int i = l; i < gene.Length; i++)
{
b.Add(gene[i]);
}
b = b.OrderBy(c => Guid.NewGuid()).ToList();
for (int i = 0; i < m; i++)
{
ans[i] = b[i];
}
for (int i = m; i < l; i++)
{
ans[i] = gene[i];
}
for (int i = 0; i < gene.Length - l; i++)
{
ans[i + l] = b[m + i];
}
}
return ans;
}
/// <summary>
/// OX变异算子
/// </summary>
/// <param name="gene">基因片段</param>
/// <returns>基因片段</returns>
public static bool[] Variation_OX(bool[] gene)
{
int[] a = new int[gene.Length];
int l, m;
bool[] ans = new bool[gene.Length];
for (int i = 0; i < gene.Length; i++)
{
a[i] = i;
ans[i] = gene[i];
}
a = a.OrderBy(c => Guid.NewGuid()).ToArray();
l = a[0];
m = a[1];
if (l < m)
{
for (int i = l; i < m; i++)
{
ans[i] = !ans[i];
}
}
else
{
for (int i = 0; i < m; i++)
{
ans[i] = !ans[i];
}
for (int i = l; i < gene.Length; i++)
{
ans[i] = !ans[i];
}
}
return ans;
}
/// <summary>
/// PBX变异算子
/// </summary>
/// <param name="gene">基因片段</param>
/// <returns>基因片段</returns>
public static int[] Variation_PBX(int[] gene)
{
int[] a = new int[gene.Length], ans = new int[gene.Length];
for (int i = 0; i < gene.Length; i++)
{
a[i] = i;
}
a = a.OrderBy(c => Guid.NewGuid()).ToArray();
int r = rand_int(0, gene.Length);
HashSet<int> set = new HashSet<int>();
for (int i = 0; i < r; i++)
{
set.Add(a[i]);
}
List<int> b = new List<int>();
for (int i = 0; i < gene.Length; i++)
{
if (set.Contains(i))
{
b.Add(gene[i]);
}
}
b = b.OrderBy(c => Guid.NewGuid()).ToList();
int num = 0;
for (int i = 0; i < gene.Length; i++)
{
if (set.Contains(i))
{
ans[i] = b[num];
num++;
}
else
{
ans[i] = gene[i];
}
}
return ans;
}
/// <summary>
/// PBX变异算子
/// </summary>
/// <param name="gene">基因片段</param>
/// <returns>基因片段</returns>
public static bool[] Variation_PBX(bool[] gene)
{
int[] a = new int[gene.Length];
bool[] ans = new bool[gene.Length];
for (int i = 0; i < gene.Length; i++)
{
a[i] = i;
}
a = a.OrderBy(c => Guid.NewGuid()).ToArray();
int r = rand_int(0, gene.Length);
HashSet<int> set = new HashSet<int>();
for (int i = 0; i < r; i++)
{
set.Add(a[i]);
}
for (int i = 0; i < gene.Length; i++)
{
if (set.Contains(i))
{
ans[i] = !gene[i];
}
else
{
ans[i] = gene[i];
}
}
return ans;
}
种群类的代码就是这样啦!接下来就是简短但又核心的遗传算法了!